
More and more applications of Natural Language Processing (NLP) are used in everyday life: When you translate a paragraph online, you are using an application of NLP, and also when you dictate a letter to a speech recognition system or when you ask questions to a voice assistant. The business world, too, is full of hidden but powerful applications of NLP.
Given this increasing applicability, researchers need to be aware of ethical concepts such as gender equality. First of all, NLP makes use of gender as an explicit variable in many places. For example, state-of-the-art systems can infer the gender of a writer with a certain degree of accuracy, based on stylistic features of the text (see Nguyen et al. (2016) for a critical survey). In an extreme case, this technology could allow employers to circumvent anonymization of job applications.
Secondly, gender is ubiquitous in NLP systems as an latent variable. To give an extreme example, think of a system that evaluates the quality of application letters. Even if the system seems harmless from a user perspective, it still might implicitly consider the applicants’ gender based on stylometric hints. If the company’s employment history has been biased towards men in the past, the system might wrongly infer that female applicants are less qualified in general. Another word for this phenomenon is proxy discrimination, as recently discussed in a NYT op-ed article.
Learning to discriminate
Let us have a closer look on gender as a latent variable. How can such a variable come into play? In NLP, most training data are derived from speech that humans have uttered somewhere in the past. Traditionally, the data are curated and annotated by experts.
But researchers like to experiment with unsupervised approaches, feeding to NLP systems gigantic amounts of raw textual data: books, social media posts, newspapers, or Wikipedia articles. Digesting those billions of utterances, systems pick up information about the morphology, syntax and semantics of a language.
It has been shown that this way, the systems also acquire a concept of gender – and one that is fraught with stereotypes. For example, many systems display the same gender biases that have been measured in humans: They associate words denoting women (“woman”, “girl”) less with math or science, and more with the arts, than male words (Caliskan et al., 2017).
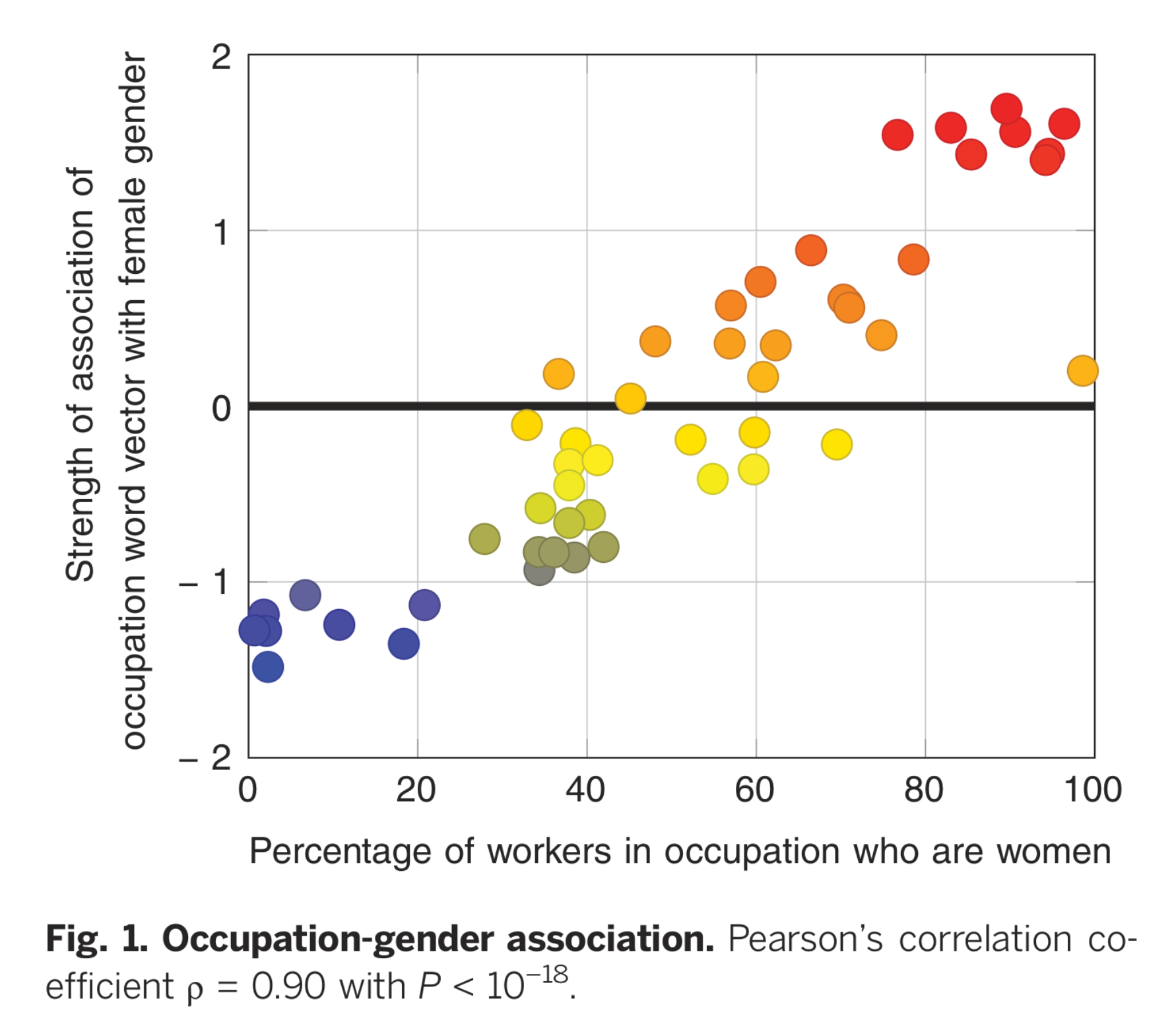 Correlation between association of word embeddings, and actual employment numbers as shown by Caliskan et al. (2017).
Correlation between association of word embeddings, and actual employment numbers as shown by Caliskan et al. (2017).
One could argue that this kind of latent gender bias is not an issue of NLP itself. On this account, the systems reflect society as it is, with all its faults. For example, the association of certain occupations with the feminine gender could be seen as an inherent property of natural language.
In the same way of thinking, a latent gender bias could be attributed to the annotators of the data, who are known to impress their own biases on the training data. To give an example, annotators asked to caption images of people tend to overspecify the gender: They would label a snowboarder as a man even if the face is not visible, and in consequence, image captioning systems learn to associate snowboards with men (Hendricks et al., 2018).
Finally, the bias could be attributed to the end-users and their preferences. For example, the fact that all major developers of voice assistants have chosen a female voice for their product is usually justified with customer expectations.
 Comparison of how different versions of a system caption the image of a snowboarder seen from behind (Hendricks et al., 2018)
Comparison of how different versions of a system caption the image of a snowboarder seen from behind (Hendricks et al., 2018)
But this argument overlooks that the elements of an NLP system have been intentionally and actively composed by people. In addition, bias does not always stem from outside, but can also emerge from the system itself (Friedman and Nissenbaum, 1996).
A military speech recognition system may be developed with mostly male soldiers in mind, which in itself many people would find ethically acceptable. But if the system would later be marketed to a general public without modifications, and would have a worse performance for female voices, a new kind of gender bias had emerged.
This scenario is not far-fetched, as one of the most popular English speech corpora has been commissioned by the U.S. military 30 years ago. In fact, the imbalance of this dataset may partly explain why the YouTube captioning system works better for male voices, or a least did so two years ago (Tatman, 2017).
An approach to avoid accidental bias in NLP systems has been proposed by Bender and Friedman (2018). In their view, a standard called data statements would require the creators of a new dataset to describe the circumstances of creation, and from the users of the dataset to reiterate this statement in a brief paragraph everytime they use it. While Bender and Friedman do not assume that all bias can be removed from systems through a proper declaration of data, they hope that the research could be better contextualized.
Apart from preventive approaches, a lot of technical solutions for de-biasing a system post hoc have been proposed (Bolukbasi et al., 2016). Furthermore, new forms of testing have been proposed to measure the gender-biasedness of NLP systems (Zhao et al., 2017). Those solutions are often tailored to a specific scenario and do not offer a systemic solution (Gonen and Goldberg, 2019). But they show that researchers have become aware of latent bias and that there is a discussion on how to avoid it.
The three roles of gender in NLP
On the other hand, systems that make explicit use of gender are problematized less frequently, even though the concept of gender has been challenged by Gender Studies and related fields for decades. For example, a recent interdisciplinary review of gender classification fails to mention the existence of constructivist or non-binary approaches to gender entirely (Lin et al., 2016).
In a first set of guidelines on the explicit use of gender in NLP, Larson (2017) proposes the following: Researchers should always specify what concept of gender they employ, even if just means quoting a classic definition. In addition, researchers should only utilize information on gender if it is necessary to achieve the research objective, and not just because the data are already available or because it is easier to ask the question “What is your gender?” than it is to ask other questions. Researchers should also specify what method they use to distinguish between genders in the annotation process.
Larson’s guidelines are a balanced ethical foundation for future NLP research into gender. However, there is one aspect that goes unmentioned by Larson: How NLP technology could me misused by malicious people to discriminate on the basis of gender. Would it be prudent to stop NLP research altogether in order to prevent abuse?
When discussing the consequences of technology, ethicists often employ the concept of dual use (Hovy and Spruit, 2016). To give an example, every system that can be used for the inference of gender from language (gender profiling) can also be used to rewrite the text such as to prevent this inference (gender obfuscation; Reddy and Knight (2016)). Another – reverse – example are systems that can detect misogynist tweets but that could also be misused to automatically generate misogynist speech).
 Style transfer experiment that could also be used for obfuscation of gender (Lample et al., 2019)
Style transfer experiment that could also be used for obfuscation of gender (Lample et al., 2019)
I believe that due its specific nature, NLP has a third use in addition to this dual use: Because they can analyze data on a large scale, NLP systems can inform a critical public of preexistent bias that manifests in natural-language texts. There are many studies where this third, sociolinguistic-diagnostic use is applied, from the analysis of letters of recommendation for male/female job applicants (Schmader et al., 2007) to the analysis of questions that sports journalists pose to male/female tennis players (Fu et al., 2016). In another example, Fast et al. (2016) analyze amateur fiction using NLP and find an abundance of gender stereotypes in every genre, irrespective of the author’s gender. As a final example, Garg et al. (2018) quantify the historical development of stereotypes based on Google Books, and show a correlation with U.S. census data.
This third use of NLP is clearly a chance to promote gender equality, even though some may criticise that all those studies assume a binary view of gender. I think that according to the guidelines by Larson (2017), this simplification can be justified as there is a clear research objective: making discrimination visible.
In my view, NLP offers chances as well a threats to gender equality, and the threats can have various sources: Preexistent societal bias, emergent bias, or the unreflected use of gender as an explicit variable. Given the promises that NLP holds for diagnosing a discriminatory use of language, there is hope that the opportunities will eventually outweigh the threats.
This is an abridged version of an essay written as part of the certificate program “Gender and Diversity Competence” at LMU Munich.
References
Emily M Bender and Batya Friedman. Data statements for natural language processing: toward mitigating system bias and enabling better science. Transactions of the Association for Computational Linguistics, 6:587–604, 2018. ↩
Tolga Bolukbasi, Kai-Wei Chang, James Y Zou, Venkatesh Saligrama, and Adam Tauman Kalai. Quantifying and Reducing Stereotypes in Word Embeddings. CoRR, 2016. URL: http://arxiv.org/abs/1606.06121, arXiv:1606.06121. ↩
Aylin Caliskan, Joanna J Bryson, and Arvind Narayanan. Semantics derived automatically from language corpora contain human-like biases. Science, 356(6334):183–186, 2017. ↩ 1 2
Ethan Fast, Tina Vachovsky, and Michael S Bernstein. Shirtless and dangerous: Quantifying linguistic signals of gender bias in an online fiction writing community. In Tenth International AAAI Conference on Web and Social Media. 2016. ↩
Batya Friedman and Helen Nissenbaum. Bias in computer systems. ACM Transactions on Information Systems (TOIS), 14(3):330–347, 1996. ↩
Liye Fu, Cristian Danescu-Niculescu-Mizil, and Lillian Lee. Tie-breaker: Using language models to quantify gender bias in sports journalism. In Proceedings of the IJCAI workshop on NLP meets Journalism. 2016. ↩
Nikhil Garg, Londa Schiebinger, Dan Jurafsky, and James Zou. Word embeddings quantify 100 years of gender and ethnic stereotypes. Proceedings of the National Academy of Sciences, 115(16):E3635–E3644, 2018. ↩
Hila Gonen and Yoav Goldberg. Lipstick on a pig: debiasing methods cover up systematic gender biases in word embeddings but do not remove them. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 609–614. 2019. ↩
Lisa Anne Hendricks, Kaylee Burns, Kate Saenko, Trevor Darrell, and Anna Rohrbach. Women also snowboard: Overcoming bias in captioning models. In European Conference on Computer Vision, 793–811. 2018. ↩ 1 2
Dirk Hovy and Shannon L Spruit. The social impact of natural language processing. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), volume 2, 591–598. 2016. ↩
Guillaume Lample, Sandeep Subramanian, Eric Smith, Ludovic Denoyer, Marc'Aurelio Ranzato, and Y-Lan Boureau. Multiple-attribute text rewriting. In International Conference on Learning Representations. 2019. URL: https://openreview.net/forum?id=H1g2NhC5KQ. ↩
Brian Larson. Gender as a Variable in Natural-Language Processing: Ethical Considerations. In Proceedings of the First ACL Workshop on Ethics in Natural Language Processing, 1–11. 2017. ↩ 1 2
Feng Lin, Yingxiao Wu, Yan Zhuang, Xi Long, and Wenyao Xu. Human gender classification: a review. International Journal of Biometrics, 8(3-4):275–300, 2016. ↩
Dong Nguyen, A Seza Doğruöz, Carolyn P Rosé, and Franciska de Jong. Computational sociolinguistics: A survey. Computational linguistics, 42(3):537–593, 2016. ↩
Sravana Reddy and Kevin Knight. Obfuscating gender in social media writing. In Proceedings of the First Workshop on NLP and Computational Social Science, 17–26. 2016. ↩
Toni Schmader, Jessica Whitehead, and Vicki H Wysocki. A Linguistic Comparison of Letters of Recommendation for Male and Female Chemistry and Biochemistry Job Applicants. Sex Roles, 57:509–514, 2007. ↩
Rachael Tatman. Gender and Dialect Bias in YouTube's Automatic Captions. In Proceedings of the First ACL Workshop on Ethics in Natural Language Processing, 53–59. 2017. ↩
Jieyu Zhao, Tianlu Wang, Mark Yatskar, Vicente Ordonez, and Kai-Wei Chang. Men Also Like Shopping: Reducing Gender Bias Amplification using Corpus-level Constraints. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, 2979–2989. 2017. ↩