
BERT models, when fine-tuned on Named Entity Recognition (NER), can have a very competitive performance for the English language. This is an overview of how BERT is designed and how it can be applied to the task of NER. In the last section, I will discuss a cross-lingual scenario.
In this post, I will assume a basic familiarity with the NER task. When I talk about implementation details of BERT (Devlin et al., 2019), I am referring to the PyTorch version that was open-sourced by Hugging Face. I have not checked if it completely matches the original implementation with respect to those details.
First let us look at what goes into the BERT model, because it is rather important for getting NER right.
Preprocessing
The input to BERT is preprocessed using WordPiece tokenization (Johnson et al., 2017), which is a technique comparable to Byte Pair Encoding (Sennrich et al., 2016). The vocabulary is trained on the pre-training data, then re-used for the fine-tuning without any modifications. For the English language model, a vocabulary of 30k tokens is used, and for the multilingual model, 110k tokens.
It is important to note that NER datasets like CoNLL-2003 are already tokenized, as the gold annotation is provided token by token. For training and evaluating BERT, the WordPiece tokenizer strictly deepens the preexisting tokenization. For every original token, the WordPiece tokenization can take one of two forms:
One-to-one tokenization. The token is in the vocabulary. In this case, it is represented by a single WordPiece.
One-to-many tokenization. The token is not in the vocabulary; in this case, the WordPiece tokenizer will split the token into a sequence of vocabulary items using a greedy longest-match approach. I call the first WordPiece of such a split the head and the other WordPieces the tails.
Tails are marked with a leading “##” by the WordPiece tokenizer. It follows that the vocabulary is divided into two distinct sets: WordPieces that can occur both in a single or in a head role on the one hand (no leading “##”), and tail WordPieces on the other hand (with a leading “##”).
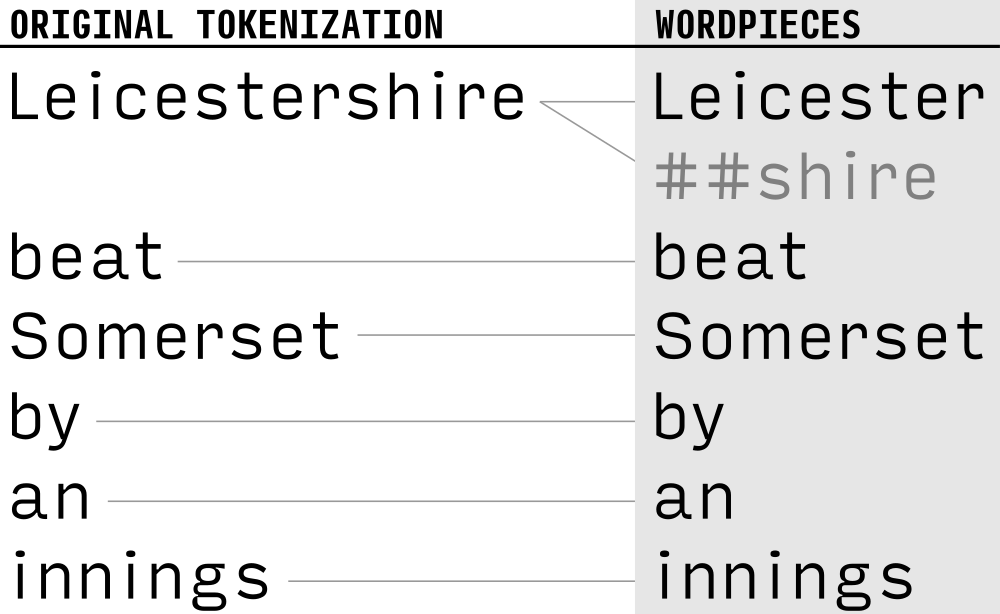 Example sentence illustrating one-to-one tokenization and one-to-many tokenization. In this example, “Leicester” is what I call a "head" WordPiece, and “##shire” is a "tail" WordPiece..
Example sentence illustrating one-to-one tokenization and one-to-many tokenization. In this example, “Leicester” is what I call a "head" WordPiece, and “##shire” is a "tail" WordPiece..
 Examples for vocabulary entries of bert-large-cased that can occur as heads or single token (left) and entries that can only occur as tails (right).
Examples for vocabulary entries of bert-large-cased that can occur as heads or single token (left) and entries that can only occur as tails (right).
WordPiece embeddings are only one part of the input to BERT. The full input is a sum of three kinds of embeddings, each with a size of 768 for BERT-Base (or 1024 for BERT-Large):
WordPiece embeddings, which like the other embeddings are trained from scratch and stay trainable during the fine-tuning step.
Segment embeddings. These kinds of segments are only relevant for tasks where a pair of sentences is classified. For NER, the embedding is insignificant, and the same segment (“A”) can be used for all tokens.
Position embeddings, which compensate for the non-recurrence of the transformer layers.
During pre-training, the input has a maximum length of 512 WordPieces. When BERT is finetuned on NER, using such long sequences is unnecessary, given that NER is usually done sentence by sentence. A sequence length of 150 should be enough, as the sentences in the English CoNLL-2003 validation set have 14.5 (original) tokens on average, and the longest sentence has 109 tokens. An alternative to having long enough sequences is a sliding window approach as described by Wu and Dredze (2019).
BERT also expects that each sentence starts with a [CLS] token and ends with a [SEP] token. These special tokens are not particularly relevant for the NER task, considering that classification is done token-wise and the special tokens have no associated tag. Nevertheless, they should be included so that the fine-tuning input is not too different from the pre-training input.
For most of the tasks BERT was evaluated on, a model with a lowercase vocabulary was used. For NER, however, the cased variant should be used and no lowercasing should be performed during preprocessing.
Architecture
BERT is a stack of Transformer layers (Vaswani et al., 2017). The variant of size “Base” has 12 layers, 12 self-attention heads, and a hidden state size of 768 per token. In total, BERT-Base has 110 million trainable parameters. The BERT-Large variant has 24 layers, 16 self-attention heads and a hidden size of 1024, which amounts to 340 million parameters.
The Transformer implements some innovative ideas which are highly relevant for the NER task:
Self-attention. Self-attention here is the idea to encode a token as the weighted sum of its context. The weights are computed as a function of the context token (key) and the token to be encoded (query), and this function has trainable weights. Other than RNN layers, which are also designed to represent tokens in context, the self-attention layer handles the context as a bag of words. This design decision is crucial:On the one hand, the parallelizability of the bag-of-words pattern makes it possible to efficiently pre-train BERT on very large corpora. On the other hand, steps need to be taken to incorporate word order in another way (see Soft Sequentiality below).
Multi-head attention. When a token is encoded as a weighted sum of its context, this is a rather coarse representation. For this reason, the designers of the Transformer introduced Multi-head attention to increase the representational capacity of the model. Multi-head attention means that the self-attention step is performed multiple times in parallel, with different weight matrices. The output of the attention heads is then concatenated and projected to the size of a single attention head.In theory, this would allow a NER model to learn different attention heads for different classes. In reality, however, the classes are not separated that way, as preliminary investigations have shown.
Stacking. As is often done with RNNs, too, multiple self-attention layers are stacked. Interspersed with the self-attention layers are token-wise feed-forward layers, and all layers are connected via skip-connections, too. But interpreting differences in the various trained layers has turned out to be difficult. With respect to NER, Wu and Dredze (2019) have shown that BERT layers to not consistently become more language-independent towards the final layer. Still, the layeredness is hoped to improve the abstractive capacity of the model, which would help to solve a task such as NER requiring complex semantics.
Soft sequentiality. This is a concept I like to use for how a transformer incorporates the sequentiality of the tokens. In an RNN, the sequence of tokens is hardwired through recurrence. On the other hand, in a transformer, the sequence is a feature of the tokens, which “softens” the sequentiality. The feature is chosen such that the model can generalize well to sequences of arbitrary length (a function of the sine wave).
 It goes without saying that word order is crucial for NER, as these made-up headlines illustrate
It goes without saying that word order is crucial for NER, as these made-up headlines illustrate
Pre-Training
The idea behind pre-training is to initialize the model with a general language-modelling capacity that can later be transferred to a multitude of NLP tasks. While for most researchers and practitioners, pre-training BERT is rather expensive, domain-specific pre-training is known to further boost performance (Xie et al., 2019). For completeness, I will summarize the pre-training step:
Two prediction tasks are used which are entirely self-supervised.
Masked Language Modelling (MLM). 15 % of the tokens in a sentence are randomly selected. The selected tokens are “masked” in a randomized procedure; the other tokens are unchanged. BERT learns to predict the original word from the output hidden states corresponding to the masked words, using a softmax layer.The masking procedure is defined as follows: In 80% of the cases, the token is replaced with a special [MASK] token. In 10% of the cases, the token is replaced with a word chosen randomly from the vocabulary. In the remaining 10%, the token is left unchanged but still included in the loss.
Next Sentence Prediction. The pre-training input consists of two segments, A and B. In 50% of the cases, the segments form a sequence in the original text. In the other cases, they have been randomly paired. From the last hidden state corresponding to the [CLS] token (sometimes called “pooled model output”), BERT learns to predict whether the B is a “next sentence” to A or not.
The originally published English models have been pre-trained on English Wikipedia, and books. From the two tasks, BERT has learnt representations of both words and sentences, which is a good starting point for fine-tuning.
Fine-Tuning for NER
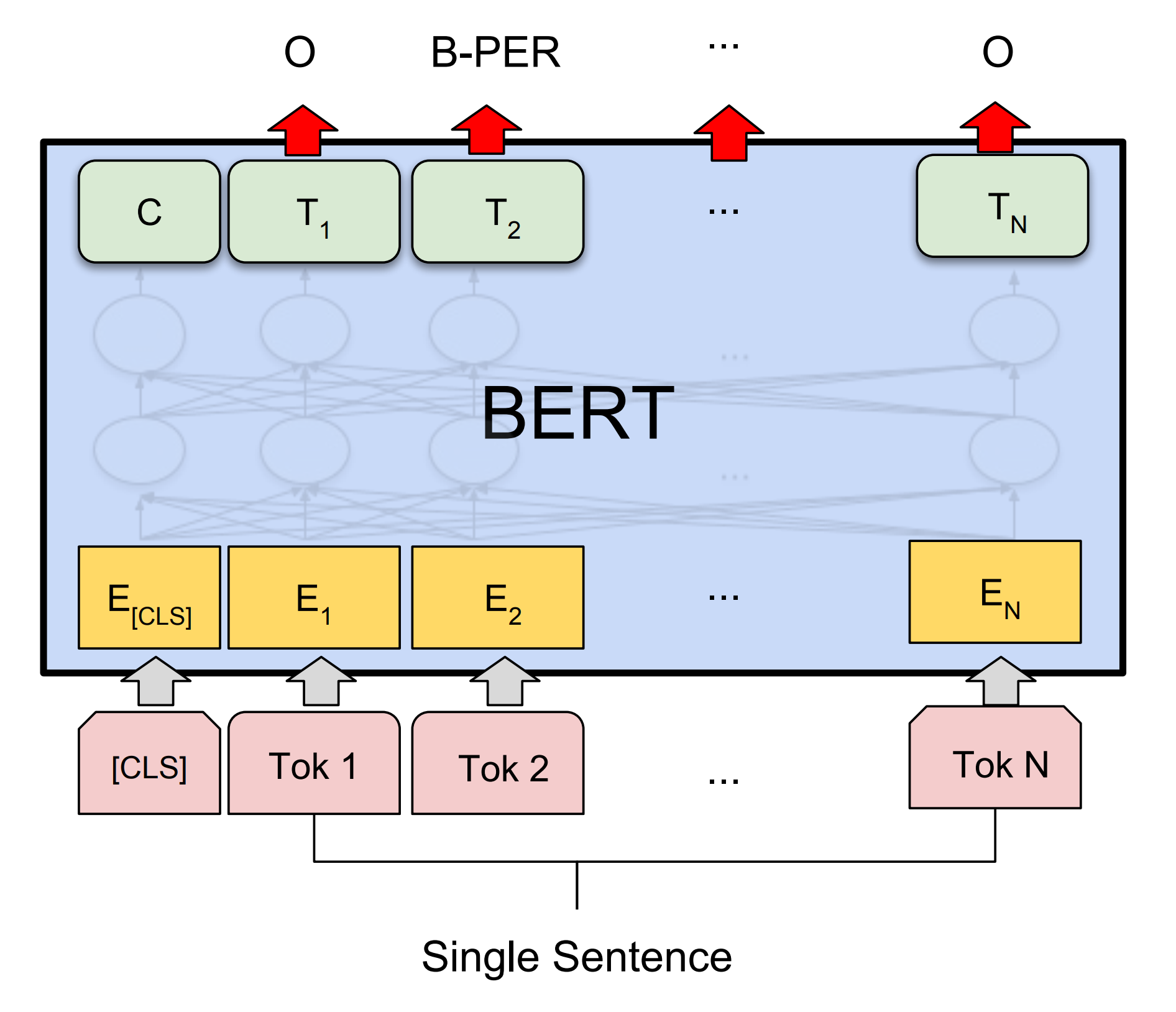 Illustration of BERT for NER (Devlin et al. 2018)
Illustration of BERT for NER (Devlin et al. 2018)
When BERT is fine-tuned on a task, the pre-trained Transformer functions as an encoder, and a randomly initialized classifier is now added on top. In the case of NER, the classifier is simply a projection from the token hidden state size to the size of the tag set, with a subsequent softmax operation to turn the scores into likelihoods. The token classifier is shared across all positions. Considering that no RNN and no CRF layer is used, the NER classifier is simpler than the classifier proposed by Lample et al. (2016), which was used to achieve 93.5 F1 with the BERT “competitor” from Facebook AI Research (Baevski et al., 2019).
To understand the classification step, it is useful to remember how the input has been preprocessed a few sections above. The one-to-many property of the WordPiece tokenizer ensures that for every token in the original dataset, there is at least one individual WordPiece that can be tagged. If an original token is split into multiple WordPieces (one-to-many case), then all WordPieces are tagged by the classifier, but only the head predictions are included in the loss and in the output at runtime. In other words, the head WordPiece serves as a proxy for the full original token. Thus, only the hidden states corresponding to single or head WordPieces are a relevant part of BERT’s last layer, while for the lower levels, all hidden states remain relevant.
During fine-tuning, both the encoder and the classifier are trained with a small learning rate. Fine-tuning is usually done for a small number of epochs, e.g. 4, and with a two-phased optimization procedure (Vaswani et al., 2017):
Warmup. For a percentage of the fine-tuning steps (default: 0.1), the learning rate is increased from 0 (default: linearly).
Decay. For remaining steps, the learning rate is decreased such that it is zero in the end (e.g. linearly).
In order to achieve the results they have published, the BERT authors have selected the best learning rate out of {5e-5, 3e-5, 2e-5} based on the validation performance.
They have reported the following results for the English CoNLL-2003 test set:
| Model size | English CoNLL-2003 Test F1 |
| BERT-Base | 92.4 |
| BERT-Large | 92.8 |
As an alternative to fine-tuning, Devlin et al. (2019) report results on a feature-based approach, too. In this case, a two-layer BiLSTM is put on top of the pre-trained BERT, and during training, the BERT parameters remain frozen. Comparing the validation set results of this approach to the validation set results of the fine-tuning approach, we can see that the more expensive fine-tuning brings an improvement for NER, however a small one:
| English CoNLL-2003 Dev F1 | |
| Fine-tuning approach | |
| BERT-Base | 96.4 |
| BERT-Large | 96.6 |
| Feature-based approach | |
| WordPiece Embeddings (first layer) | 91.0 |
| Second-to-Last Hidden | 95.6 |
| Last Hidden | 94.9 |
| Weighted Sum Last Four Hidden | 95.9 |
| Concat Last Four Hidden | 96.1 |
| Weighted Sum All 12 Layers | 95.5 |
Cross-Lingual Transfer
Cross-lingual NER is a scenario where there are enough data for a source language (usually English), and only little data for a target language. For this post I will look at the most extreme case, where there are only evaluation data, and no training data at all, for the target language. This case is often called zero-shot transfer.
The team behind BERT has open-sourced a multilingual BERT model (sometimes called mBERT) that allows for experiments in this direction. Right now, the only documentation available is in a README on GitHub.
mBERT has been trained on 104 Wikipedias in different languages. Generally, the corpora have been treated as if they were from a single language: There is no explicit denotation of the input language. This way, the BERT architecture di not have to be changed and mBERT can now be used with any previously unseen language (e.g. Alemannic, which was not included as it has the 108th largest Wikipedia).
For the vocabulary creation and the pre-training, relatively small languages were upsampled to a degree. I do not know whether the random replacing of words and the random pairing of sentences was done across languages or not – there would be arguments for and against doing so.
A systematic study on the cross-lingual effectiveness of mBERT has been conducted by Wu and Dredze (2019). Their experiment was set up as follows:
Fine-tuning. For NER, they first fine-tune bert-base-multilingual-cased on English CoNLL-2003, choosing a combination of learning rate, batch size and number of epochs that has the best performance on the English validation set
Zero-shot evaluation. Then they evaluate the model on the test set of another language (German, Spanish and Dutch). They want to find out whether mBERT can generalize to other languages without having seen target-language examples for the fine-tuning task.
They report the following results for the CoNLL-2002/2003 languages:
| EN | DE | NL | ES | ZH | |
| Supervised | 91.97 | 82.82 | 90.94 | 87.38 | 93.17 |
| Zero-shot SOTA (Xie et al. 2019) | 57.76 | 71.25 | 72.37 | – | |
| Zero-Shot | – | 69.56 | 77.57 | 74.96 | 51.90 |
Zero-shot transfer is of course not better than supervised learning, but mBERT clearly outperforms the previous zero-shot state of the art by Xie et al. (2018).
Pires et al. (2019) perfomed the same experiment and even provide numbers for all source–target combinations of the CoNLL data:
| ↓ Fine-tuning \ Eval → | EN | DE | NL | ES |
| EN | 90.70 | 69.74 | 77.36 | 73.59 |
| DE | 73.83 | 82.00 | 76.25 | 70.03 |
| NL | 65.46 | 65.68 | 89.86 | 72.10 |
| ES | 65.38 | 59.40 | 64.39 | 87.18 |
It is especially interesting that zero-short transfer to Dutch seems to benefit more from a Spanish source than from English or German.
The slight differences between the two tables can be explained by implementation details and different hyperparameters, considering that Pires et al. (2019) did not do any hyperparameter tuning.
To conclude, BERT is a good basis to achieve state-of-the-art results on Named Entity Recognition, and the fine-tuning for this task is relatively simple to implement. The multilingual BERT model even allows for an easy cross-lingual transfer, but the results here still have room for improvement.
References
Alexei Baevski, Sergey Edunov, Yinhan Liu, Luke Zettlemoyer, and Michael Auli. Cloze-driven pretraining of self-attention networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 5363–5372. 2019. ↩
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 4171–4186. 2019. ↩ 1 2
Melvin Johnson, Mike Schuster, Quoc V Le, Maxim Krikun, Yonghui Wu, Zhifeng Chen, Nikhil Thorat, Fernanda Viégas, Martin Wattenberg, Greg Corrado, and others. Google’s multilingual neural machine translation system: enabling zero-shot translation. Transactions of the Association for Computational Linguistics, 5:339–351, 2017. ↩
Guillaume Lample, Miguel Ballesteros, Sandeep Subramanian, Kazuya Kawakami, and Chris Dyer. Neural architectures for named entity recognition. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 260–270. 2016. ↩
Telmo Pires, Eva Schlinger, and Dan Garrette. How multilingual is multilingual bert? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 4996–5001. 2019. ↩ 1 2
Rico Sennrich, Barry Haddow, and Alexandra Birch. Neural machine translation of rare words with subword units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 1715–1725. 2016. ↩
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in neural information processing systems, 5998–6008. 2017. ↩ 1 2
Shijie Wu and Mark Dredze. Beto, bentz, becas: the surprising cross-lingual effectiveness of bert. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 833–844. 2019. ↩ 1 2 3
Jiateng Xie, Zhilin Yang, Graham Neubig, Noah A Smith, and Jaime G Carbonell. Neural cross-lingual named entity recognition with minimal resources. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, 369–379. 2018. ↩
Qizhe Xie, Zihang Dai, Eduard Hovy, Minh-Thang Luong, and Quoc V Le. Unsupervised data augmentation. arXiv preprint arXiv:1904.12848, 2019. ↩